Tie in and fill your day with a good read about knots!

And if this spawned your interest like mine you will find a good jump-off point here and here:
If there is any discussion or argument about electric mobility these days the topic of range and battery-aging is coming up rather quick.
Every once in a while you also hear these awesome stories about electric cars achieving total-driven-distances outrageously huge compared to combustion engine cars…
But what is it then, how does a battery in an electric car age over time and mileage? Given that car manufacturers seem to settle on a ca. 150.000km total-driven-miles baseline for giving a battery-capacity percentage guarantee. Something like…
The future owners of ID. models won’t need to worry about the durability of their batteries either, as Volkswagen will guarantee that the batteries will retain at least 70 per cent of their usable capacity even after eight years or 160,000 kilometres.
Volkswagen Newsroom
or
Model S and Model X – 8 years (with the exception of the original 60 kWh battery manufactured before 2015, which is covered for a period of 8 years or 125,000 miles, whichever comes first).
Model 3 – 8 years or 100,000 miles, whichever comes first, with minimum 70% retention of Battery capacity over the warranty period.
Model 3 with Long-Range Battery – 8 years or 120,000 miles, whichever comes first, with minimum 70% retention of Battery capacity over the warranty period.
Tesla
So. Guarantees are one thing. Reality another. There’s an interesting user-driven survey set-up where Tesla owners can hand in their cars data thus participate in the survey.
And it yields results (getting updated as you read…):
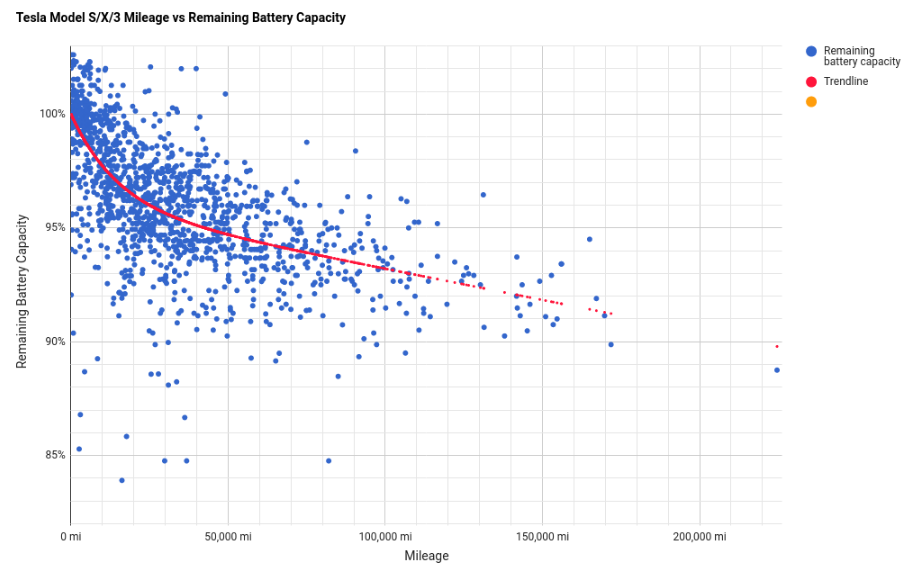
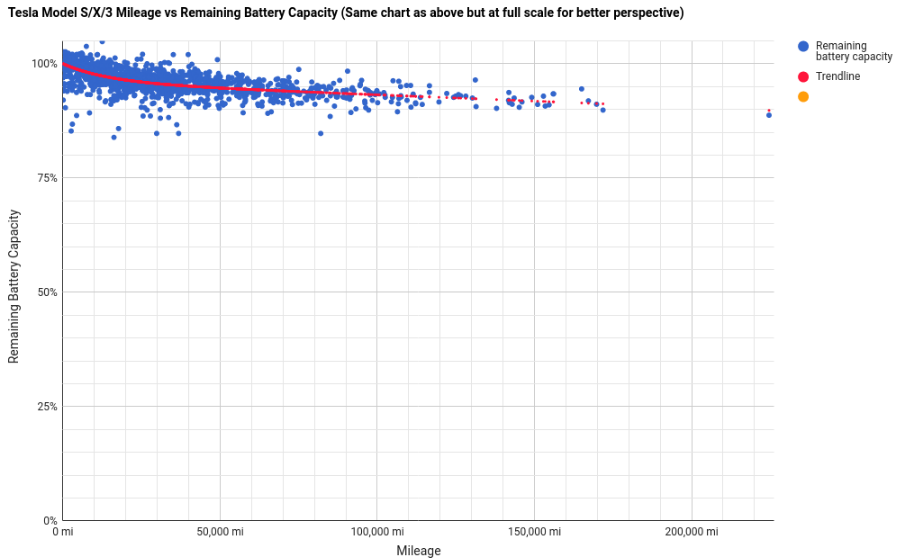
In a nutshell: It seems there is a good chance that your Tesla car might have an above 90% original-specified-battery-capacity after the guaranteed 100.000 miles and even after 150.000 miles (241.000km)…
Good news that is! Given that the average household will do about or less than 20.000 km/year it would mean over 12 years of use and the car still would hold 90% of battery charge. The battery being the most expensive single component on an electric car this is extremely good news as it’s unlikely that the battery will be the reason for the car to be scraped after this mileage.
I/O is getting faster in servers that have fast programmable NICs and non-volatile main memory operating close to the speed of DRAM, but single-threaded CPU speeds have stagnated. Applications cannot take advantage of modern hardware capabilities when using interfaces built around abstractions that assume I/O to be slow. We therefore propose a structure for an OS called parakernel, which eliminates most OS abstractions and provides interfaces for applications to leverage the full potential of the underlying hardware. The parakernel facilitates application-level parallelism by securely partitioning the resources and multiplexing only those resources that are not partitioned.
https://dl.acm.org/citation.cfm?doid=3317550.3321426
As you might know humans are going to go “back to the moon“. At least when you ask a certain eCommerce mogul.
We have been there already. 40+ years ago. And since then we have unlearnt how to do it.
Just to give an impression of what we as humans where capable to achieve 40 years ago:

There’s a whole collection of these photos freely available for further digging. Go there and spend a day!
Imagine: Humans flew there and back. With 60s tech. What can we do now when we want it?
Of course. The important bit is not really flying there and back. The most important thing for me is perspective.
Look at that small blue-white marble. We should reset our perspectives regularly.
Artificial Intelligence is used more and more to achieve tasks only humans could do before. Especially in the areas that need a certain technique to be mastered AI goes above and beyond what humans would be able to do.
In this case a team has implemented something that takes video inputs and generates a comic strip from this input. Imagine it to look like this:


In this paper, we propose a solution to transform a video into a comics. We approach this task using a
Paper
neural style algorithm based on Generative Adversarial Networks (GANs).

They even made a nice website you can try it yourself with any YouTube Video you want:

Have you ever asked yourself what those generations coming after us will know about what was part of our culture when we grew up? As much as computers are a part of my story a bit of gaming also is.
From games on tape to games on floppy disks to CDs to no-media game streaming it has been quite a couple of decades. And with the demise of physical media access to the actual games will become harder for those games never delivered outside of online platforms. Those platforms will die. None of them will remain forever.
Hardware platforms follow the same logic: Today it’s the new hype. Tomorrow the software from yesterday won’t be supported by hardware and/or operating systems. Everything is in constant flux.
Emulation is a great tool for many use-cases. But it probably won’t solve all challenges. Preserving access to software and the knowledge around the required dependencies is the mission of the Video Game History Foundation.

Video game preservation matters because video games matter. Games are deeply ingrained in our culture, and they’re here to stay. They generated an unprecedented $91 billion dollars in revenue in 2016. They’re being collected by the Smithsonian, the Museum of Modern Art, and the Library of Congress. They’ve inspired dozens of feature films and even more books. They’re used as a medium of personal expression, as the means for raising money for charity, as educational tools, and in therapy.
Video Game History Foundation
And yet, despite all this, video game history is disappearing. The majority of games that have been created throughout history are no longer easily accessible to study and play. And even when we can play games, that playable code is only a part of the story.
Last week we were approached by Prof. Dr. Nicole Zillien from Justus-Liebig-University in Gießen/Germany. She explained to us that she currently is working on a book.
In this book an empirical analysis is carried out on “quantified-self” approaches to real life problems.
With the lot of information and data we had posted on our personal website(s) like this blog and the “loosing weight” webpage apparently we qualified for being mentioned. We were asked if it would be okay to be named in the book or if we wanted to be pseudonymized.
Since everything we have posted online and which is publicly accessible right now can and should be quoted we were happy to give a go-ahead. We’re publishing things because we want it to spur further thoughts.

It will be out at the end of 2019 / beginning of 2020. As soon as it is out we hope to have a review copy to talk about it in this blog once again.
We do not know what exactly is being written and linked to us – we might as well end up as the worst example of all time. But well, then there’s something to learn in that as well.
Since a couple of months we are trying harder to learn a foreign language.
And as we excepted it is very hard to get a proper grasp on speaking the language. Especially since it is a very different language to our mother tongue.
And while comfortably interacting with digital assistants around the house every day in english and german the thought came up: why don’t these digital assistants help with foreign language listening and speaking training?
I mean Google Assistant answers questions in the language you have asked them. Siri and Alexa need to know upfront in which language you are going to ask questions. But at least Alexa can translate between languages…
But with all seriousness: Why do we not already have the obvious killer feature delivered? Everyone could already have a personal language training partner…
Did you ever start a horde of virtual machines and a complicated vm-only network set-up just to simulate a medium complex network and the interaction of nodes in that network? Well that’s a tiresome, error-prone and labour intensive process. Fear no more, there’s a tool to the rescue.
“Mininet creates a realistic virtual network, running real kernel, switch and application code, on a single machine (VM, cloud or native), in seconds, with a single command:”
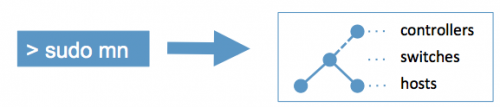
“Because you can easily interact with your network using the Mininet CLI (and API), customize it, share it with others, or deploy it on real hardware, Mininet is useful for development, teaching, and research. Mininet is also a great way to develop, share, and experiment with OpenFlow and Software-Defined Networking systems.
Source: http://mininet.github.com/
The second edition of the book “Security Engineering” by Ross Anderson is available as a full download. It’s quite a reference and a must-read for anybody with an interest in security (which for example all developers should have).
“When I wrote the first edition, we put the chapters online free after four years and found that this boosted sales of the paper edition. People would find a useful chapter online and then buy the book to have it as a reference. Wiley and I agreed to do the same with the second edition, and now, four years after publication, I am putting all the chapters online for free. Enjoy them – and I hope you’ll buy the paper version to have as a conveient shelf reference.”

Source 1: http://www.cl.cam.ac.uk/~rja14/book.html
Wikipedia describes latency this way:
“Latency is a measure of time delay experienced in a system, the precise definition of which depends on the system and the time being measured. In communications, the lower limit of latency is determined by the medium being used for communications. In reliable two-way communication systems, latency limits the maximum rate that information can be transmitted, as there is often a limit on the amount of information that is “in-flight” at any one moment. In the field of human-machine interaction, perceptible latency has a strong effect on user satisfaction and usability.” (Wikipedia)
Given that it’s quite important for any developer to know his numbers. Since latency has a huge impact on how software should be architected it’s important to keep that in mind:

Source: http://www.eecs.berkeley.edu/~rcs/research/interactive_latency.html
SPAUN or Semantic Pointer Architecture Unified Network is a promising next step in the pursuit to simulate a human brain. Built upon the Nengo Neural Simulator scientists at the University in Waterloo/Ontario were able to report on their first break-through results.
In 2013 there will be a book from Oxford University press called ‘How to build a brain’ which will describe in depth what made the astonishing results possible.
But what are the results?

Well that looks like number recognition. In fact that’s what it is. SPAUN – that’s how the scientists refer to their frankenstein-brain – is capable of solving 8 different tasks now. One of them is number recognition. There are videos of all 8 tasks being performed.
The Semantic Pointers are named after the pointers usually common in computer science:
“Higher-level cognitive functions in biological systems are made possible by semantic pointers. Semantic pointers are neural representations that carry partial semantic content and are composable into the representational structures necessary to support complex cognition.
The term ‘semantic pointer’ was chosen because the representations in the architecture are like ‘pointers’ in computer science (insofar as they can be ‘dereferenced’ to access large amounts of information which they do not directly carry). However, they are ‘semantic’ (unlike pointers in computer science) because these representations capture relations in a semantic vector space in virtue of their distances to one another, as typically envisaged by connectionists. “
Source 1: http://nengo.ca/build-a-brain
Source 2: http://nengo.ca/build-a-brain/spaunvideos/
In November 1998 there was a book released about file system design taking the Be File System as the central example.
“This is the new guide to the design and implementation of file systems in general, and the Be File System (BFS) in particular. This book covers all topics related to file systems, going into considerable depth where traditional operating systems books often stop. Advanced topics are covered in detail such as journaling, attributes, indexing and query processing. Built from scratch as a modern 64 bit, journaled file system, BFS is the primary file system for the Be Operating System (BeOS), which was designed for high performance multimedia applications.
You do not have to be a kernel architect or file system engineer to use Practical File System Design. Neither do you have to be a BeOS developer or user. Only basic knowledge of C is required. If you have ever wondered about how file systems work, how to implement one, or want to learn more about the Be File System, this book is all you will need.”
 If you’re interested in the matter I definitely recommend reading it – it’s available for free in PDF format and will help to understand what those file system patterns are all about – even in terms of things we still haven’t gotten from our ‘modern filesystems’ today.
If you’re interested in the matter I definitely recommend reading it – it’s available for free in PDF format and will help to understand what those file system patterns are all about – even in terms of things we still haven’t gotten from our ‘modern filesystems’ today.
Source 1: http://www.nobius.org/~dbg/
This October I had the pleasure to fly to Tokyo for the second time in 2012.
The development unit of Rakuten Japan was hosting the 7th Rakuten Technology Conference in Rakuten Tower 1 in Tokyo.
The schedule was packed with up to 6 tracks in parallel. From research to grass-roots-development a lot of interesting topics.
[nggallery id=4]
Source 1: http://tech.rakuten.co.jp/rtc2012/
Source 2: Recorded Lectures
Some weeks ago I heard about a new audio codec which is being developed as open source – very similar to vorbis – the previous open source approach to audio codecs.
This time it seems that they’ve got some standardization into the play so it might be more successful than vorbis was.

“Opus is a totally open, royalty-free, highly versatile audio codec. Opus is unmatched for interactive speech and music transmission over the Internet, but also intended for storage and streaming applications. It is standardized by the Internet Engineering Task Force (IETF) as RFC 6716 which incorporated technology from Skype’s SILK codec and Xiph.Org’s CELT codec.”
![]()
Source 1: http://www.opus-codec.org/
Source 2: http://auphonic.com/blog/2012/09/26/opus-revolutionary-open-audio-codec-podcasts-and-internet-audio/
Source 3: http://tools.ietf.org/html/rfc6716
It’s been some months years since the once Microsoft Research Project got public and Microsoft started offering it’s great Photosynth service to the public.
I’ve been using the Microsoft panoramic and Photosynth tools for years now and I tend to say that they are the best tools one can get to create fast, easy and high-quality panoramic images.
There is photosynth.net to store all those panoramic pictures like this one from 2008:
The photosynth technology itself contains several other interesting technologies like SeaDragon which allows high quality image zooming on current internet connection speeds.
This awesome technology is as of now available on the iPhone (3GS and upwards) and it’s better than all the other panoramic tools I’ve used on a phone.



Source 1: Photosynth articles from the past
Source 2: Photosynth in Wikipedia
Source 3: Photosynth on iPhone App Store
Since we’re at it – we not only took the new Mono garbage collector through it’s paces regarding linear scaling but we also made some interesting measurements when it comes to query performance on the two .NET platform alternatives.
The same data was used as in the last article about the Mono GC. It’s basically a set of 200.000 nodes which hold between 15 to 25 edges to instances of another type of nodes. One INSERT operation means that the starting node and all edges + connected nodes are inserted at once.
We did not use any bulk loading optimizations – we just fed the sones GraphDB with the INSERT queries. We tested on two platforms – on Windows x64 we used the Microsoft .NET Framework and on Linux x64 we used a current Mono 2.7 build which soon will be replaced by the 2.8 release.
After the import was done we started the benchmarking runs. Every run was given a specified time to complete it’s job. The number of queries that were executed within this time window was logged. Each run utilized 10 simultaneously querying clients. Each client executed randomly generated queries with pre-specified complexity.
The Import
Not surprisingly both platforms are almost head-to-head in average import times. While Mono starts way faster than .NET the .NET platform is faster at the end with a larger dataset. We also measured the ram consumption on each platform and it turns out that while Mono takes 17 kbyte per complex insert operation on average the Microsoft .NET Framework only seems to take 11 kbyte per complex insert operation.
The Benchmark
Let the charts speak for themselves first:

click to enlarge

click on the picture to enlarge

click on the picture to enlarge
As you can see on both platforms the sones GraphDB is able to work through more than 2.000 queries per second on average. For the longest running benchmark (1800 seconds) with all the data imported .NET allows us to answer 2.339 queries per second while Mono allows us to answer 1.980 queries per second.
The Conclusion
With the new generational garbage collector Mono surely made a great leap forward. It’s impressive to see the progress the Mono team was able to make in the last months regarding performance and memory consumption. We’re already considering Mono an important part of our platform strategy – this new garbage collector and benchmark results are showing us that it’s the right thing to do!
UPDATE: There was a mishap in the “import objects per second” row of the above table.
We want to show you something today: Not everybody has an idea what to think and do with a graph data structure. Not even talking about a whole graph database management system. In fact what everybody needs is something to get “in touch” with those kinds of data representations.
To make the graphs you are creating with the sones GraphDB that much more touchable we give you a sneak peak at our newest addition of the sone GraphDB toolset: the VisualGraph tool.
This tool connects to a running database and allows you to run queries on that database. The result of those queries is then presented to you in a much more natural and intuitive way, compared to the usual JSON and XML outputs. Even more: you can play with your queries and your data and see and feel what it’s like to work with a graph.
Expect this tool to be released in the next 1-2 months as open source. Everyone can use it, Everyone can benefit from it.
Oh. Almost forgot the video:
(Watch it in full screen if you can)
Since we all need documentation I thought it would be a great idea to create a one-pager which helps every user to remember important things like query language syntax.
You can download the cheatsheet here:

Download here.
I am proud to anounce that there’s a video publicly available which shows parts and projects Microsoft Research is working on currently. It’s great to see theses projects, concepts and ideas become publicly available one by one:
“Craig Mundie, chief research and strategy officer of Microsoft, presents “Rethinking Computing,” a look a how software and information technology can help solve the most pressing global challenges we face today. Part of UW’s Computer Science and Engineering’s Distinguished Lecture Series, Mundie demonstrates a number of current and future-looking technologies that show how computer science is changing scientific exploration and discovery in exciting ways. He discusses the role of new science in solving the global energy crisis, and answer questions from the audience.”

Source: http://www.uwtv.org/programs/displayevent.aspx?rID=30363&fID=6021
Almost three years ago I wrote about this nice little Regular Expression Tool which provides not only a RegEx-Builder but also a clean and nice interface to test and play.
It was a CodeProject sample project in that time and as it turns out it became a full blown version 3!
Obviously the user interface was revamped completely:
 So you now not only get the Testing and playing but also a Regular Expression Library, a cool How-To, a more useable design mode and you can even output your final regular expressions to C#, VB.NET or managed C++!
So you now not only get the Testing and playing but also a Regular Expression Library, a cool How-To, a more useable design mode and you can even output your final regular expressions to C#, VB.NET or managed C++!
Great stuff! Even better is the fact that it does not come at any costs. Despite the fact that there’s a registration you can just get your free license on their website.
Source 1: http://www.ultrapico.com/Expresso.htm
Source 2: want some espresso?

I was in desperate need for an DDate equivalent running on Windows. DDate is an unix implementaion of date accoridng to the erisian calendar described in the principia discordia.
I only found some C Implementations. And since it’s fun to do I ported the original Discordian Date C code to C#.
You can download the C# sourcecode, licensed under CC-BY-NC here.
I also created a web page which displays the current discordian date and offers you to convert any gregorian date into discordian date representation.
This page can be accesses here. You can call another page with parameters and you only will get the ddate output back:
for example: http://ddate.schrankmonster.de/DiscordianDate.aspx?year=2009&month=6&day=9
Source 1: http://ddate.schrankmonster.de/
Source 2: http://dropbox.schrankmonster.de/dropped/SharpDDateLib.zip

After not less than 3 and a half hour Songbird finished with importing the iTunes library I am using for about 6 years.
The first impression is: Cool, it’s got plugins!
The second impression is: Booh, it wants to restart (while stopping the music) to install!
It’s not faster than iTunes. And this is a sad thing, because the only thing I hoped it would be was faster. It’s not – the UI it’s as fast and responsive as iTunes’ UI – at best. With just a few clicks the whole songbird window went into sleep mode and the well known beachball came into the play.
Even worse: for some strange reason Songbird consumes considerably more CPU time while just sitting there and playing an MP3 than iTunes does:
![]()
18,7% CPU load used by songbird just by playing an mp3 (no filtering, no visualisation, no nothing)
![]()
2,3% CPU load for iTunes while doing exactly the same. Even the same mp3 was played.
iTunes even takes less memory… oh dear: A long way to go for the Songbird team.
Oh dear. Another hyped protocol/platform from Google… oh wait. It’s not from Google. It’ all started in Xerox PARC…
There are several papers that describe what Google now claims to have developed…

left: Xerox PARC Paper; right: Google Wave
Conclusion: Go and read old Papers. As it turns out almost all newly hyped things have been described in papers from years ago.
Source 1: http://www.waveprotocol.org/whitepapers/operational-transform
Source 2: http://doi.acm.org/10.1145/215585.215706
