OpenStreetMap data is huge. Like really really huge. Its the whole planet earth afterall. So huge in fact that so far I am using a separate server to host my very own, up-to-date OpenStreetMap planet instance that I can query against with the Overpass-API format.

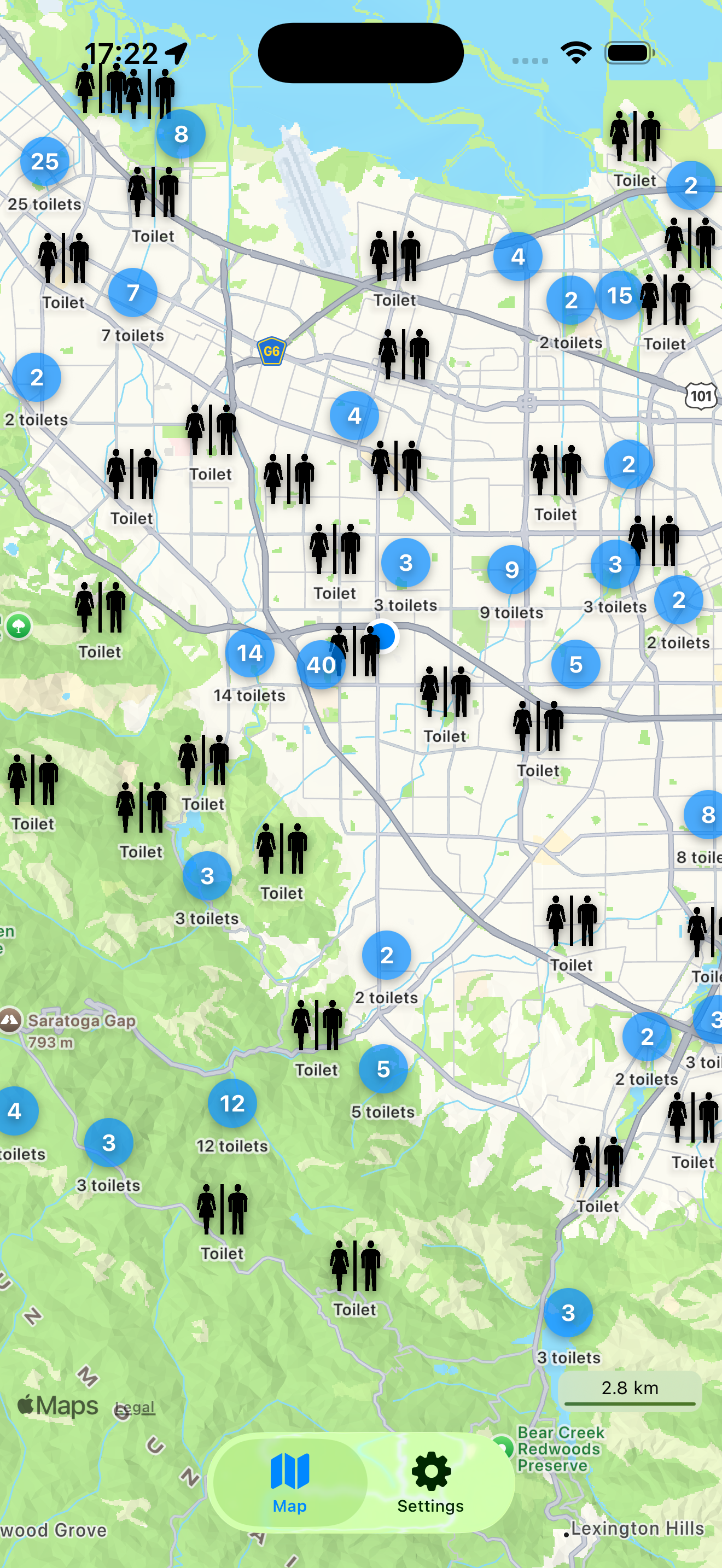
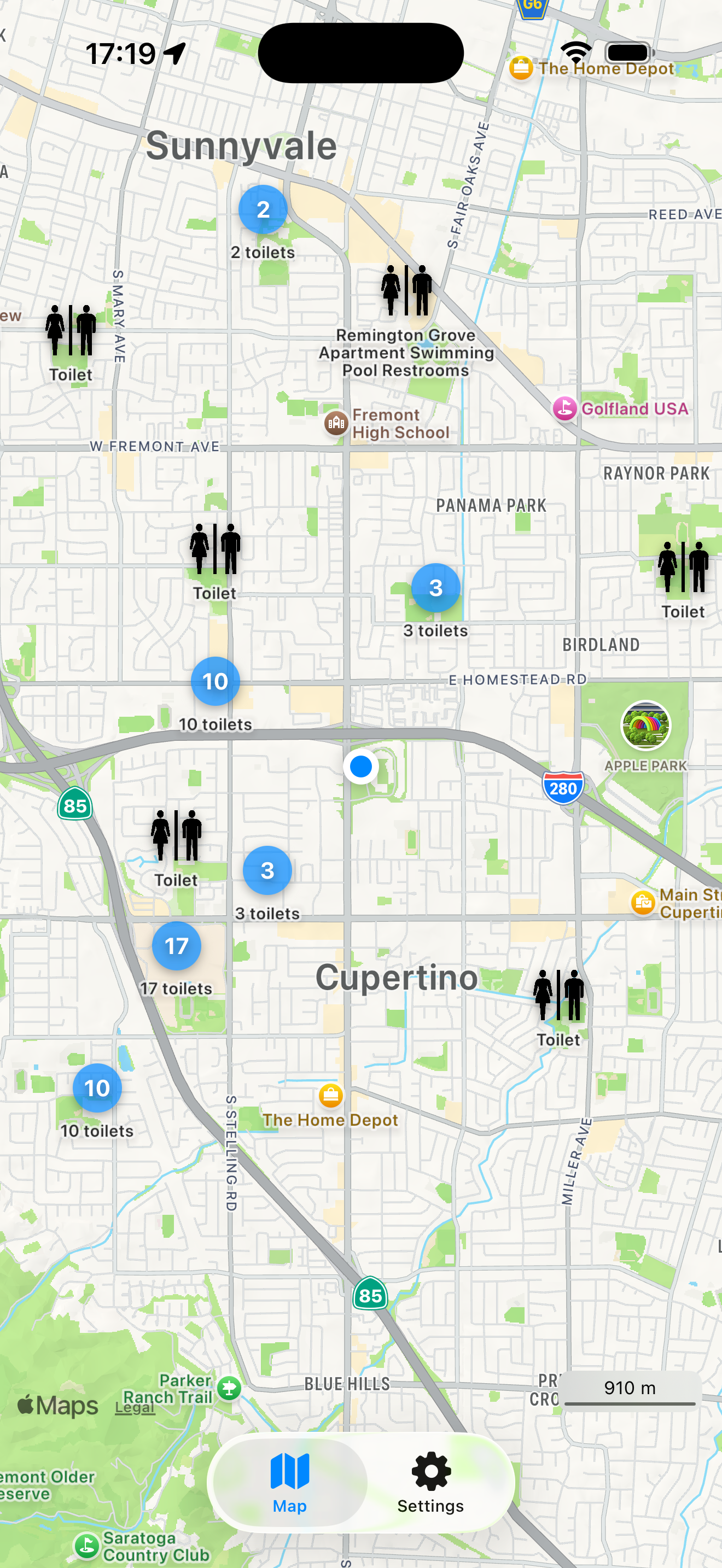
Overpass is quite handy for all sorts of use-cases, like searching for very specific information on the map – like amenities (toilets, benches, ATMs,…).
So a query like this (you have to set bbox to the actual bounding box coordinates):

Will produce a data-set representing all toilets inside of that bounding box on the map. This will look a lot like this:
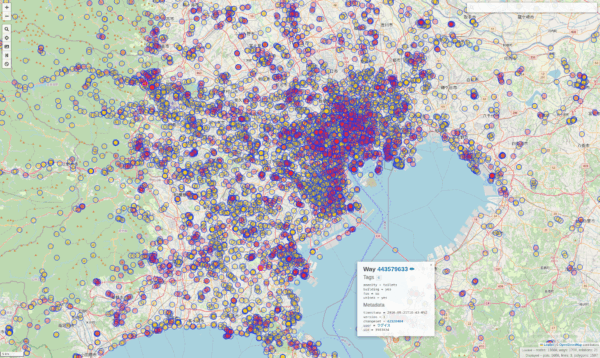
And of course this is lots of effort to sieve through all the millions of nodes inside of the bounding-box and filtering out the right ones.
To produce the example above my server needs roughly 27630 milliseconds or just under 28 seconds to process all that data (which is 13668 toilets….).

For the amount of data and the processing required this isn’t all that bad. The caveat: if you rerun that request it will take the almost exact same time. It’s just a lot of data and the limit here is SSD-read speeds and compute capacity.
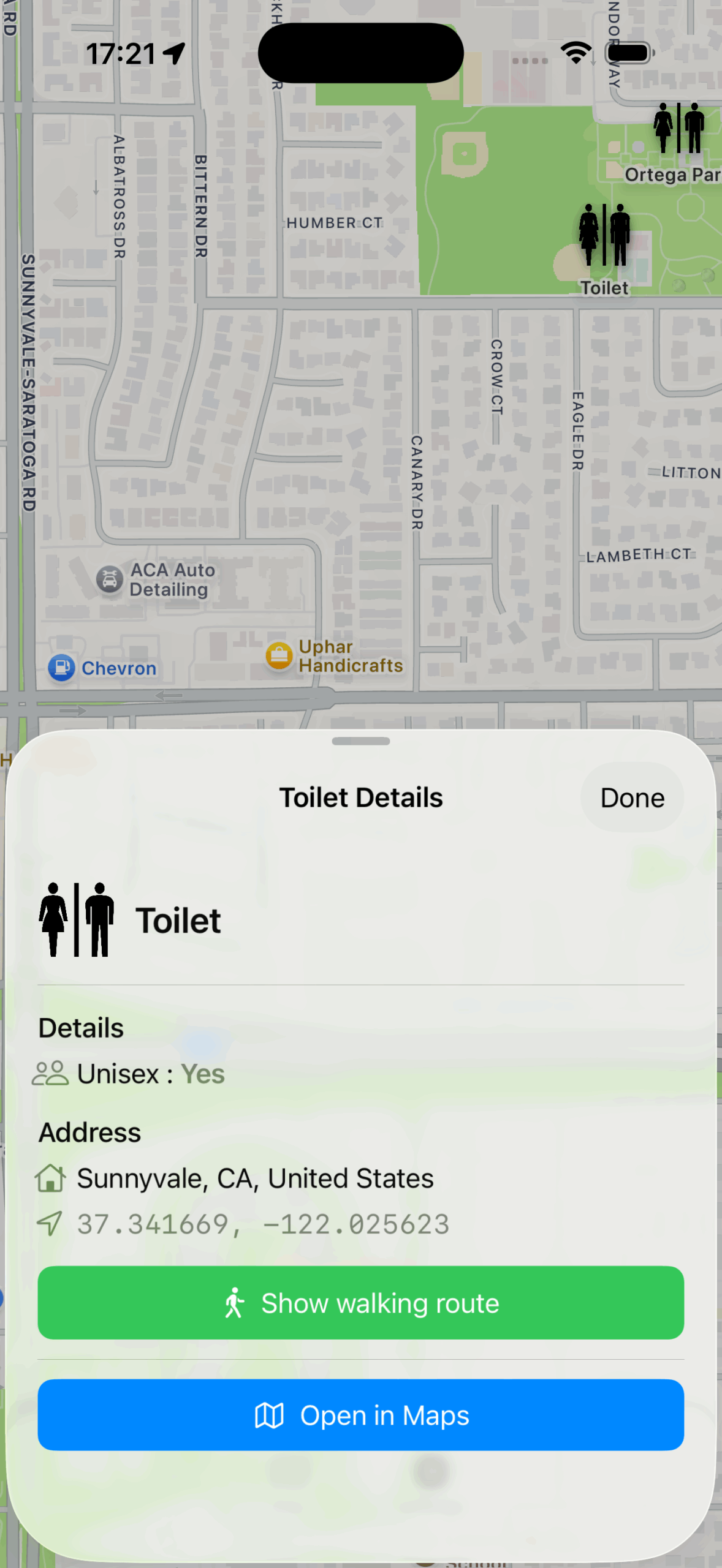
Now I happen to have written an app that makes use of Overpass-Queries as its main purpose: It finds you amenities like Toilets. It does implement it’s own caching on client side, so for users the map is fast after the actual load, no matter how often they come back to that section of the map. But that client-side caching does not scale with lots of users.
With the recent rewrite of my app the userbase has expanded. Therefore lots more users actually use my app. And apparently they run lots of overpass queries. To relieve server load and required resources I came up with a simple vibe code prompt:
I have the following idea and would like to develop a plan with you for a specification on how this idea can best be implemented with Codex.
Current situation:
So far, I have been running a full OpenStreetMap Overpass Server. This comes with enormous resource requirements because the entire OSM world map, including all metadata, must be managed and kept up to date.
My use case (filtering for toilets/amenities), however, is relatively limited and can be summarized into fixed queries. When I look at how much data is actually affected worldwide, I would estimate that instead of the 500 GB world map, less than 100 MB of real useful data is relevant for my application.
The idea:
I want to program a transparent Overpass API proxy (https://wiki.openstreetmap.org/wiki/Overpass_API) that only responds to appropriately formulated Overpass queries from API users.
The query:
node
[amenity=toilets]
({{bbox}});
out body meta;>;out skel qt;
I want the Overpass API proxy to cache all potential data (with a configurable TTL) and query results from an underlying Overpass API server, fill the cache, and return bounding-box results according to the query.
Any bounding boxes should be queryable — but always with a fixed amenity.
The task:
Create a specification, program flow, and implementation instructions for a program that uses Node.js as the base for the Overpass API proxy and Redis as the intermediate storage/cache.
The whole thing should be deployable as a Docker container and have both a configurable TTL and a configurable upstream Overpass API server.
Bonus:
It would be a plus if the actual amenity could be flexibly chosen.
All metadata returned by the Overpass server should be correctly stored and, upon request, reassembled into bounding boxes by the Overpass API proxy.
Several steps with OpenAIs Codex and Cursor led to an actual implementation of that idea.
The result: The exact same query, when run again, takes less than 2 seconds now:

I have, as usual, open sourced that tool. So you can try for yourself, if you happen to have a use case. If you want you can try it out best with Overpass Turbo in your browser, while setting up the Overpass-Proxy on a server (docker instructions included in the box).
Sourcecode: https://github.com/bietiekay/Overpass-Proxy