You can get a grasp at the beautiful side of science with visualizations and algorithms that output visual results.
This is the example of producing lots and lots of complex data (houses!) from a small set of input data. It is widely used in game development but also can be helpful to generate parameterized test and simulation environments for machine learning.
So before sending you over to the more detailed explanation the visual example:
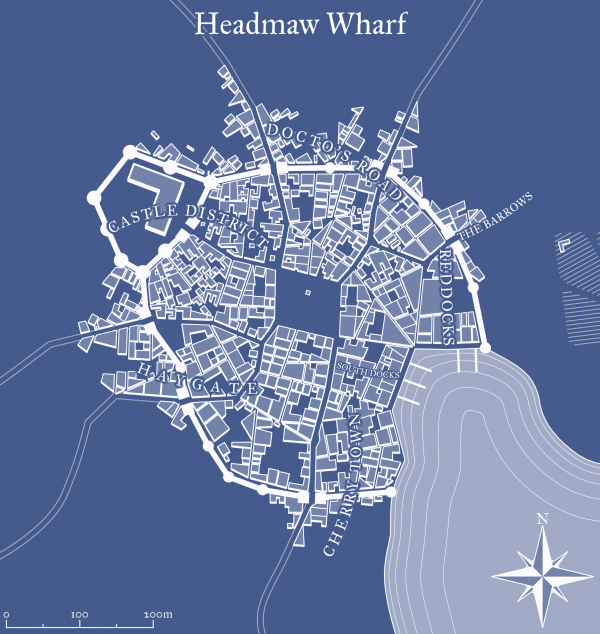
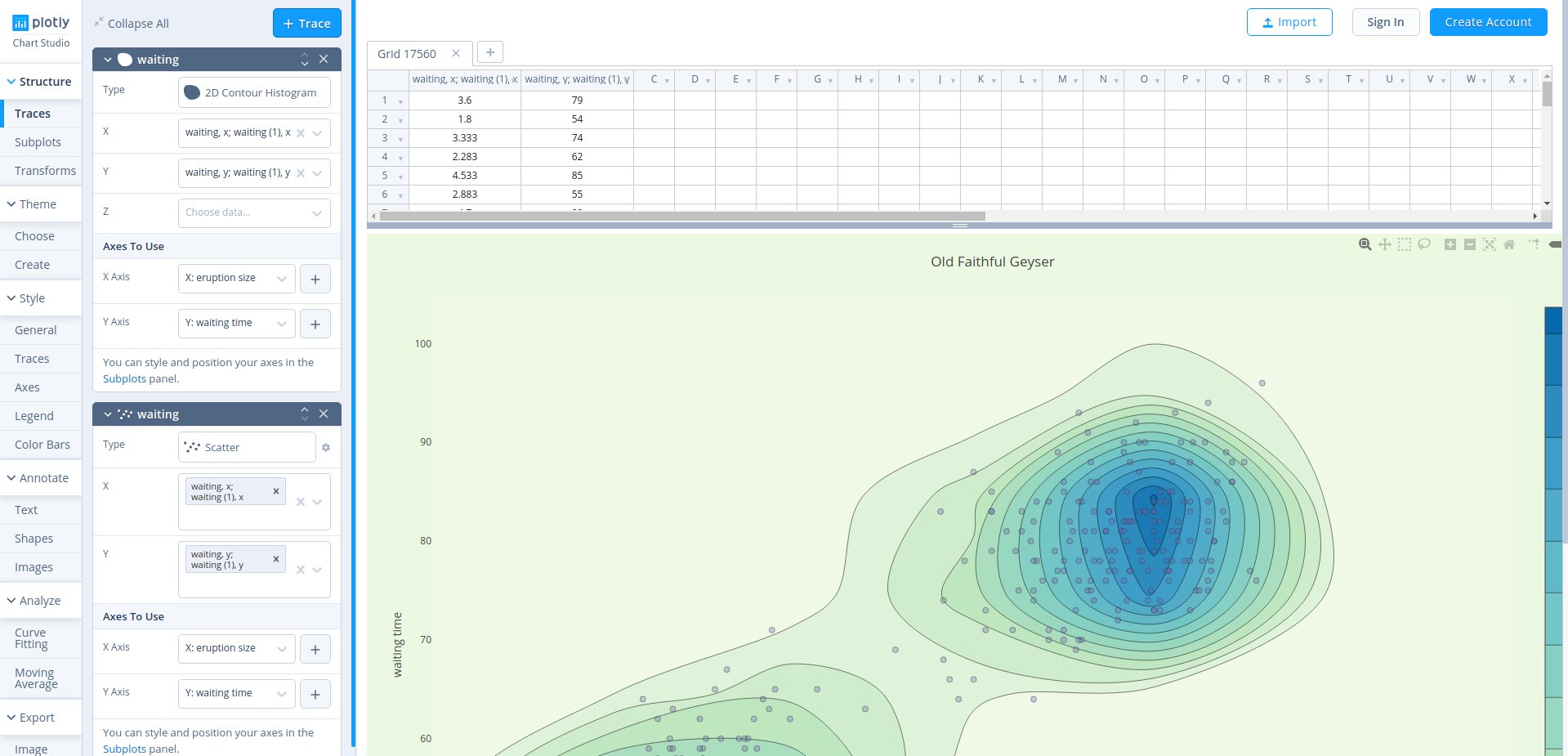
This is a lot of different house images. Those are generated using a program called WaveFunctionCollapse:
WFC initializes output bitmap in a completely unobserved state, where each pixel value is in superposition of colors of the input bitmap (so if the input was black & white then the unobserved states are shown in different shades of grey). The coefficients in these superpositions are real numbers, not complex numbers, so it doesn’t do the actual quantum mechanics, but it was inspired by QM. Then the program goes into the observation-propagation cycle:
On each observation step an NxN region is chosen among the unobserved which has the lowest Shannon entropy. This region’s state then collapses into a definite state according to its coefficients and the distribution of NxN patterns in the input.
On each propagation step new information gained from the collapse on the previous step propagates through the output.
On each step the overall entropy decreases and in the end we have a completely observed state, the wave function has collapsed.
It may happen that during propagation all the coefficients for a certain pixel become zero. That means that the algorithm has run into a contradiction and can not continue. The problem of determining whether a certain bitmap allows other nontrivial bitmaps satisfying condition (C1) is NP-hard, so it’s impossible to create a fast solution that always finishes. In practice, however, the algorithm runs into contradictions surprisingly rarely.
Wave Function Collapse algorithm has been implemented in C++, Python, Kotlin, Rust, Julia, Go, Haxe, JavaScript and adapted to Unity. You can download official executables from itch.io or run it in the browser. WFC generates levels in Bad North, Caves of Qud, several smaller games and many prototypes. It led to new research. For more related work, explanations, interactive demos, guides, tutorials and examples see the ports, forks and spinoffs section.