A week ago I had written about another mechanical hard drive that was about to bite the dust in our houses elaborate set-up.
Not having time for a full-day-of-focus I postponed the upgrade to this saturday. With the agreement of the family as they are suffering through the maintenance period as well.
The upgrade would need cautious preparation in order to be doable in one sitting. And this was also meant to be some sort of disaster-recovery-drill. I would restore the house central docker and service infrastructure from scratch along this.
And this would need to happen:
- all services, zfs pools, docker containers, configurations needed to be double checked for full backup – as this would be used to restore all (ZFS snapshots are just the bomb for these things!)
- the main central docker server would have to go down
- get all hard disks ripped out
- SSDs put in and properly configured

- get a fresh Ubuntu 18.04 LTS set-up and booting from ZFS on a NVMe SSD (bios update(s)!, secure boot disabling, ahci enabling, m.2 instead of sata express switching…you get the idea)
- get the network set-up in order: upgrading from Ubuntu 16.04 to 18.04 means ifupdown networking was replaced by netplan. Hurray! Not.
- get docker-ce and docker-compose ready and set-up and all these funky networkings aligned – figure out in this that there are major issues with IPv6 in docker currently.
- pull in the small number of still needed mechanical hard disks and import the ZFS pools
- start the docker builds from the backup (one script \o/)
- start the docker containers in their required order (one script \o/)
Apart from some hardware/bios related issues and the rather unexpected netplan introduction everything went fairly good. It just takes ages to see data copied.
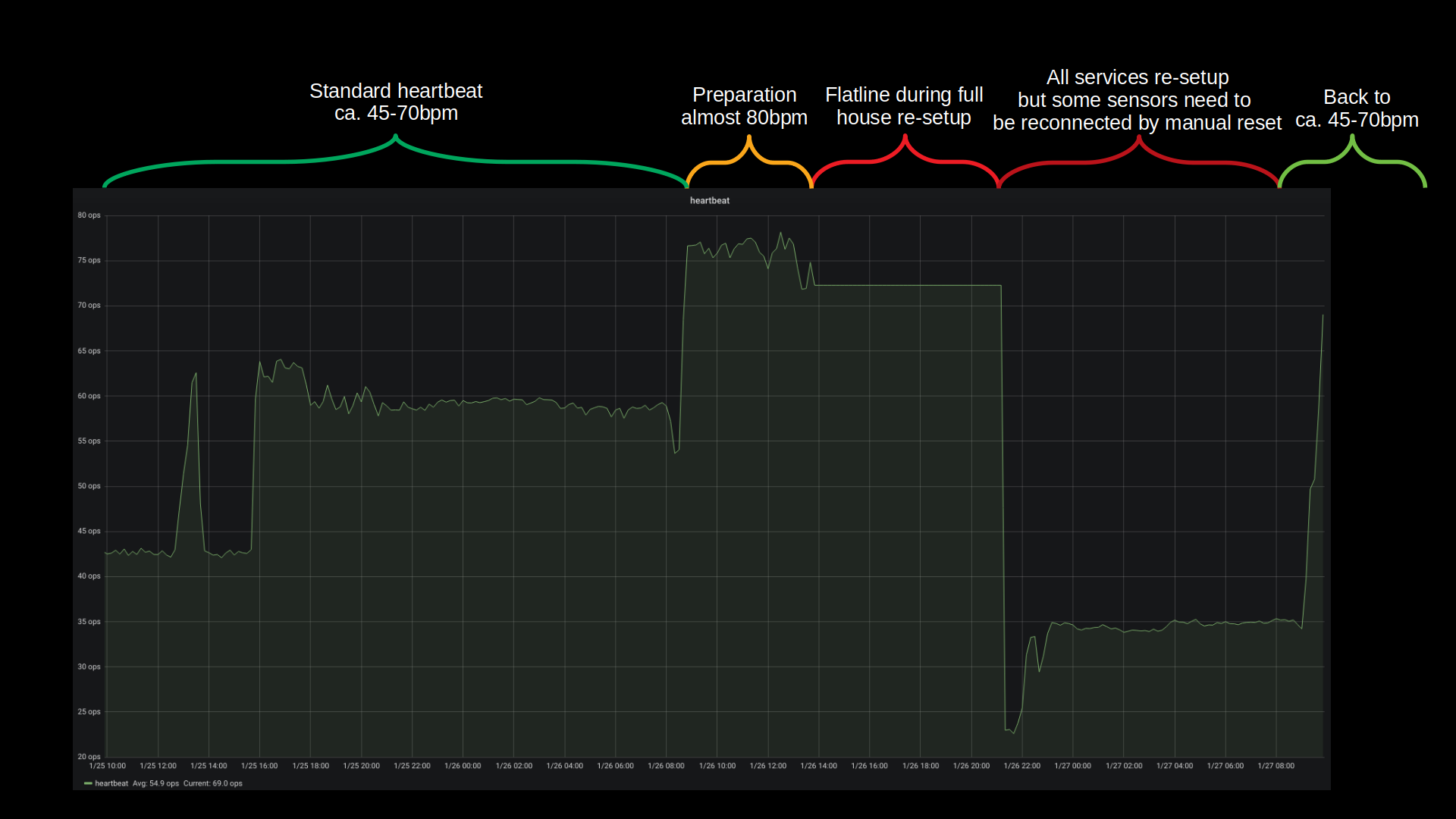
Bandwidth was the only real issue with this disaster recovery. All building blocks seemed to fall into place and no unplanned measure had to be taken. The house systems went partially down at around 12:30 and were back up 10 hours later 22:00. Of course non-automated things like internet kept working and all switches were only manual push-buttons. So everything could be done still but with a lot less convenience.
All in all there are more than 40 vital docker container based services that get started one after the other and interconnect to deliver a full house home automation. With the added SSD performance this whole ship is much much more responsive to activities. And hopefully less prone to mechanical defects.
Backup and Disaster-Preparations showed to be practical and working well. There was no beat missed (except sensor measure values during the 10 hours downtime) and no data lost.
What could be done better: It could be much more straight forward when there were less dependencies on external repositories / docker-hub. Almost all issues that came up with containers where from the fact that the maintainers had just a day before introduced something that kept them from spinning up naturally. Bad luck. But that can be helped! There’s now a multi-page disaster-recovery-procedure document that will be used and updated in the future.
Oh and what speeds am I seeing? The promissed 3 Gbyte/s read and write speeds are real. It’s quite impressive to see 4-digit megabyte/s values in iotop frequently.
I almost forgot! During this exercise I had been in the server room less than 30 minutes. But I was on a warm and nice work-desk set-up I am using in the house as much as I can – and I will tell you about it in another article. But the major feature of this work-desk set-up is that it is (a) a standing desk and (b) has a treadmill under it. Yes. Treadmill.
You will get pictures of the set-up in that mentioned article, but since I had spent more than 10 hours walking on saturday doing the disaster recovery I want to give you a glimpse of what such a set-up means:
