Japan November 2019: Day 20









…quite amazing.
I’ve upgraded just before the Japan travelling to the current iPhone generation. I was expecting some improved battery life but I did not dare to think I would get THIS.
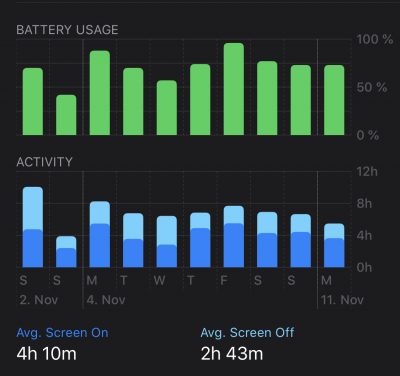
I’ve taken the last 3 generations of iPhones on trips to Japan and they all went through the same exercises and quite comparable day schedules.
The amount of navigation, screen-time, taking pictures and just browsing the web / translating led to all 3 previous generations to be out-of-juice just around half-day.
Not this generation. Apparently something has changed. Not really in terms of screen time – screen on-time got better, but not as great as the overall usage time of the device with screen off.
In regards of how much power and runtime I am getting out of the device without having to reach for a batter pack or power supply is astonishing. I am using my Apple Watch for navigation clues so I am not really reaching out for the phone for that. But that means the phone is constantly used otherwise to make pictures, payments, translations….
I am comfortably leaving all battery packs and chargers at home when all the time before I was charging the phones at lunchtime for the first time. I usually had to charge 2 times a day to get through.
With this generations iPhone 11 Pro I am getting through the whole day and reach the hotel just before getting down to 20%.
I am still using it all throughout the day. But this is such a relief that I am confidently getting through a full day of fun. Thumbs up Apple!
The 50th Day of the Season of The Aftermath. The Fluxday marking the approach of the Season of Chaos.
Chaos (season)