I am using some Raspberry Pis to monitor the areas around the house. Mainly because it’s awesome to see how many animals are roaming around in your garden throughout the day. On the Pi I am using the current Debian image and motion to interface with an USB webcam.
Now I wanted to include sensory data into the webcam images – like the current temperature. The nice thing about h.a.c.s. is that it can deliver every sensors data in nice and easy to use JSON. The only challenge now is to get the number into motion.
First of all I need to get the URL together where I can access sensor data for the right sensor. In this case it’s the sensor called “Schuppen” – an outdoor sensor measuring the current temperature around the house.
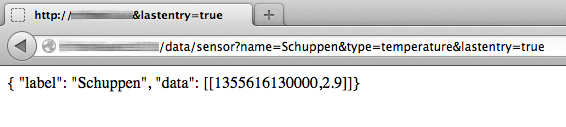
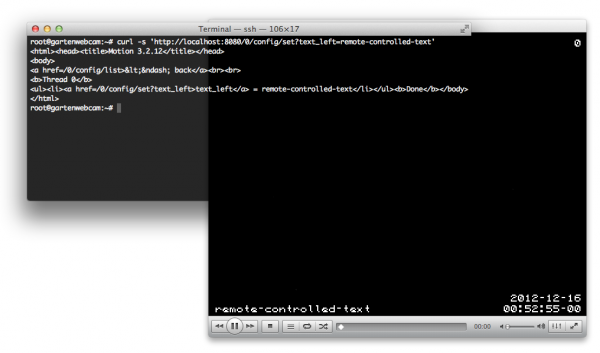
Now there is an easy way to ‘feed’ data into a running motion instance. Motion offers a control port and allows to set the text_left and text_right properties. Doing a simple GET request there allows us to set the text to – in this example – “remote-controlled-text”:
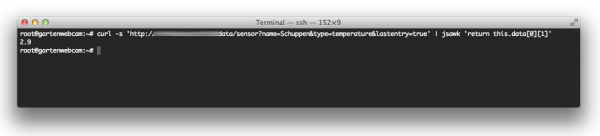
So – that’s how the text is set – now how to get the temperature value, and just that, out of the JSON response of h.a.c.s.? Easy – use jsawk!
With all that a very small shell script is quickly hacked:
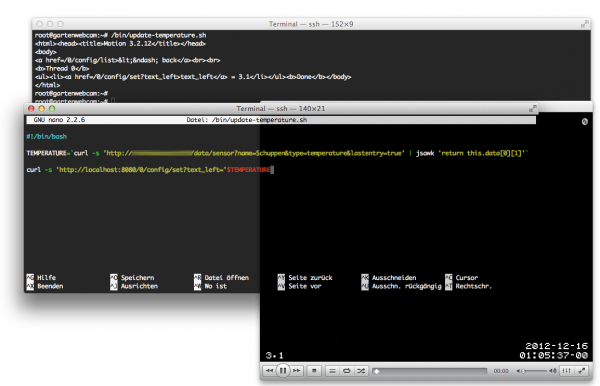
If you want to copy that into your editor, here’s the code:
#!/bin/bash
TEMPERATURE=`curl -s 'http://hacs/data/sensor?name=Schuppen&type=temperature&lastentry=true' | jsawk 'return this.data[0][1]'`
curl -s 'http://localhost:8080/0/config/set?text_left='$TEMPERATURE
Localhost port 8080 is the port and adress of the motion control server .
To have the webcam updated regularly, I added it to crontab and from now on the current temperature is in every webcam image – hurray!
Source 1: motion
Source 2: jsawk