About 2 years ago I sat down and wrote a filesystem. Well not from scratch but using the great FUSE (Filesystem in Userspace) framework. I’ve released it as open-source later on Github:
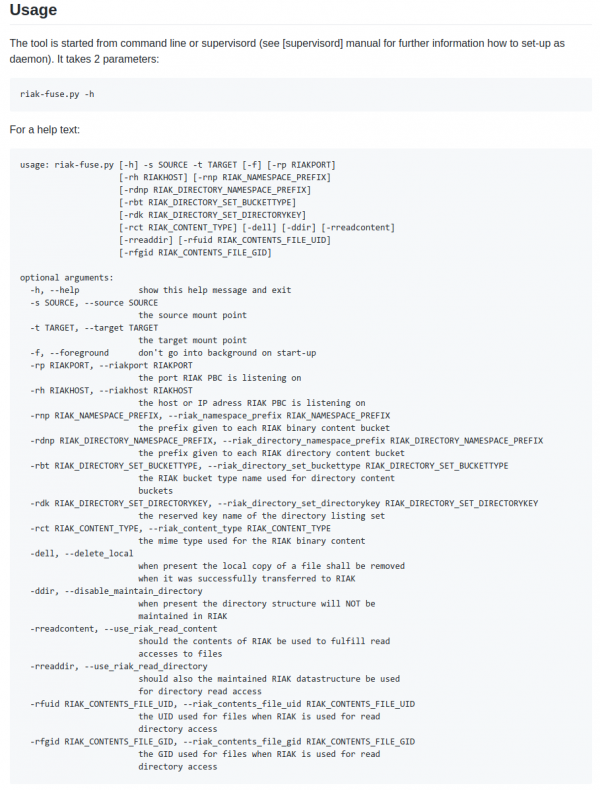
This script acts as glue between a local file storage mount point and RIAK. It is targeted at specific use cases when local mount-points need to be migrated to RIAK without changing the applications accessing those mount point. Think of it as a transparent RIAK filesystem layer with multiple options to control it’s behavior regarding local files.
riakfuse
I had a very specific purpose in mind when I wrote this: There was a local filesystem that got filled up and because of technical restrictions we were not able to resize it or even completely copy it without interrupting the service using the data stored there.
Since we were already using the RIAK Key-Value Database for certain binary loads the idea came up to also utilize this key-value concept for a filesystem.
The idea now is: You have a local filesystem that holds a lot of folders and files already and you want to gradually want to move it to new grounds.
This migration needed to happen with minimal service interruptions assuming that there is constant reading and writing happening.
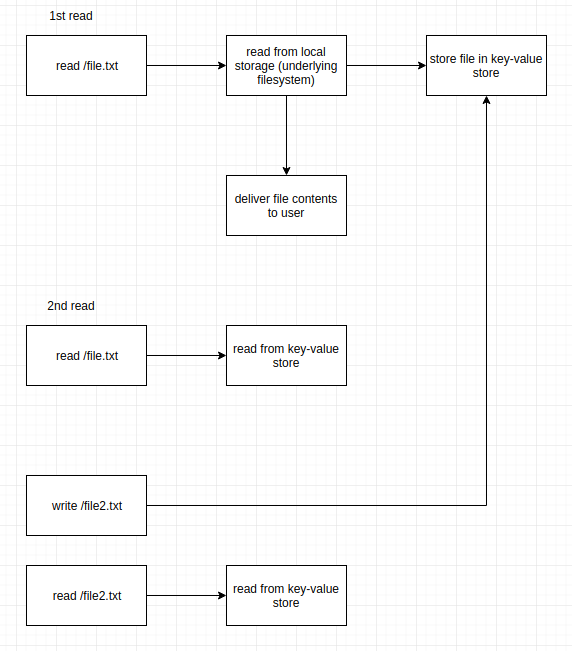
In this riak-fuse project I’ve written an overlay filesystem that steps between the application and the underlying “old”-filesystem. It looks and behaves identical to the application reading and writing.
But, depending on the mode you have chosen while mounting, every file read will at first be read from the “old”-filesystem and after successfull read stored into the key-value store.
On the next read it will be read from the key-value store directly.
The same applies for writing. Riak-fuse will write either to both, local storage and key-value store or just to the key-value store.
So in a nutshell: Data is slowly but surely on each access transferred over to the key-value store and load + storage space is slowly moving over from the local storage to the key-value store.
To facilitate this there are a lot of options for this script:
This all comes with ready-to-use docker and docker-compose files for you to try out.
Also it might interest you as an extremely simplified example of how to write an actual file system module for FUSE in Python.
Disclaimer: This effectively is my first python script as well as fuse module. Don’t be too hard on your judgement.